Dermatologist-level classification of skin cancer with deep neural networks
Esteva A, Kuprel B, Novoa R A, et al. Dermatologist-level classification of skin cancer with deep neural networks[J]. Nature, 2017, 542(7639): 115.
简介
论文核心
利用inceptionv3训练129450张图片,对皮肤癌的诊断达到可媲美皮肤科医生的水平
论文任务
本文的分类实际上只针对两种皮肤癌,也就产生了本文的两个任务:角质形成细胞癌(keratinocyte carcinomas)vs 良性脂溢性角化病(benign seborrheic keratoses);恶性黑色素瘤 vs 普通的痣,在 21 位经过认证的皮肤科医生的监督下,测试了它在活检证实的临床图像上的性能。
第一例代表最常见的癌症的识别,第二例代表了最致命的皮肤癌的识别。
论文贡献
- 数据构建上,积累了129,450张临床图像(几乎覆盖所有皮肤癌的种类),其中包括3,374张皮肤镜图片,均提前活检确认过
- 提出一种新的皮肤病分类方法,将2,032种皮肤病归类为757种训练分类,再归纳为9/3种推理分类,经过对比可知,此方法可以提高分类精度
- 提出的基于GoogleNet Inception v3卷积神经网络的深度学习方案可利用手机摄像头完成,可以帮助医生与病人随时自动检测,以及省去人工提取特征,改为端到端的学习方法且更具有泛化性
方法
数据
之前的皮肤癌分类系统使用的数据集较小,通常小于1000张图像,于是本文作者就在互联网上收集了129450张图像,其中3374张是皮肤镜图像(皮肤镜是皮肤科医生诊断时使用的专业手持设备)
在这些图像中共包含2032中疾病,但是训练分类器的时候,作者将输出的类别精简为757类
数据集划分
测试集和验证集中的模糊图像和far-away图像被移除,但训练集中保留。
数据集中包含统一损害的不同视角图像,或同一病人身上相似损害的不同图像。这些图像在划分训练集和验证集时不会混淆。
采用图像EXIF元数据,存储特定信息和由CNN特征检索到的最近邻图像,创建一个无向图,相连的图像定义为相似的。图中连接的图像不能被划分到训练集/验证集。测试集均来自独立的、高质量的斯坦福医院。测试集和训练集/验证集之间不存在重合(同一损伤的不同视角)
- Exif:Exif 是一种图象文件格式,它的数据存储与 JPEG 格式是完全相同的。实际上 Exif 格式就是在 JPEG 格式头部插入了数码照片的信息,包括拍摄时的光圈、快 门、白平衡、ISO、焦距、日期时间等各种和拍摄条件以及相机品牌、型号、 色彩编码、拍摄时录制的声音以及全球定位系统(GPS)、缩略图等。简单地Exif=JPEG+拍摄参数。
分类算法
递归算法,利用分类法生成训练类别(疾病具有临床或视觉上的相似性),仅有一个超参数maxClassSize。
- 避免产生过于细粒度的训练类别,导致没有足够的数据来正确学习;
- 避免产生过于粗糙的训练类别,导致数据量过多的类别,算法会偏向于它们
提出一种新的皮肤病分类方法,将2,032种皮肤病归类为757种训练分类,再归纳为9/3种推理分类,经过对比可知,此方法可以提高分类精度。
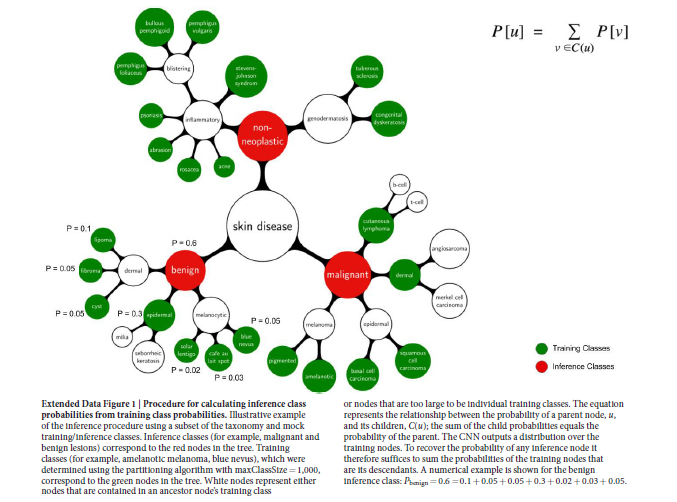
三个根结点表示一般疾病:良性肿瘤、恶性肿瘤、无肿瘤,作为第一验证策略。根结点的孩子结点代表具有相似临床治疗方案的疾病,作为第二验证策略。
从根节点开始遍历,计算当前节点所属类别包含的图片数量,以上面的Benign节点为例,它包含的图片数就是该节点下面所有叶子节点的图片数目和,若该数目超出设定的阈值(本文为1000),则递归计算该节点的所有子节点,否则满足条件,将该节点设为用来训练的类别,即757之一。具体流程如下,思路还是很清晰的,也很合理


分类结果
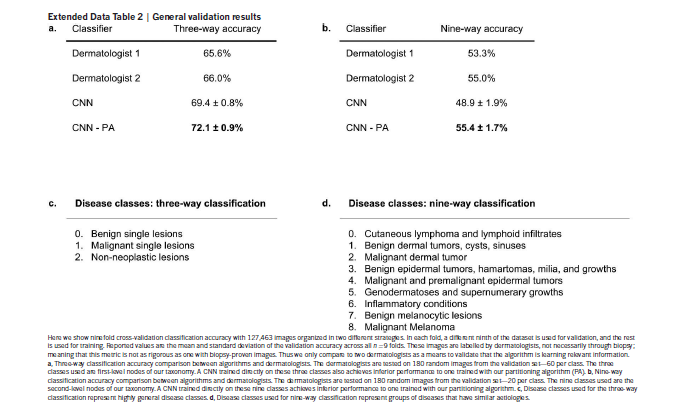
性能指标
本文的对比,自始至终都在和医生的水平对比,而非单一的准确率,所要达到的目标是接近医生的诊断,而非一味的用100%准确率衡量。
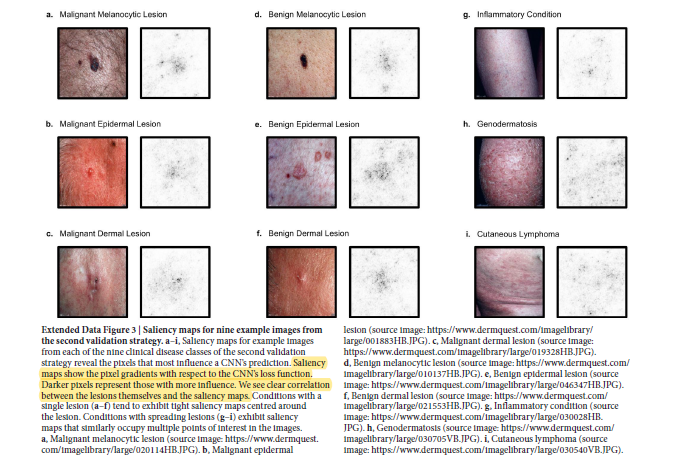
敏感性、特异性;t-SNE二维聚类图;混淆矩阵;特征图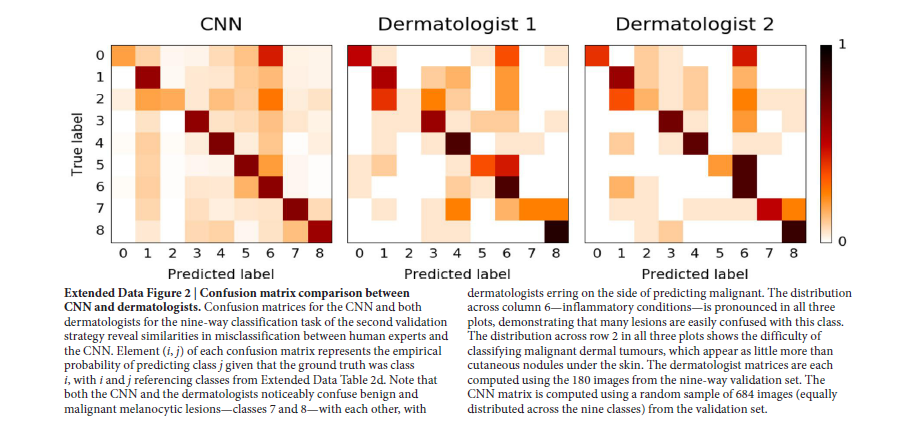
实验
训练
迁移学习:在ImgaeNet上预训练的Google’s Inception v3 CNN,修改最后分类层的参数,训练所有层的参数。
参数及数据增强
- All layers of the network are finetuned using the same global learning rate of 0.001 and a decay factor of 16 every 30 epochs.
- We use RMSProp with a decay of 0.9, momentum of 0.9 and epsilon of 0.1.
- During training, images are augmented by a factor of 720. Each image
is rotated randomly between 0° and 359°. The largest upright inscribed rectangle
is then cropped from the image, and is flipped vertically with a probability of 0.5.
Inference algorithm
每个推理类别都是一个包含后代(特定训练结点)的结点。(红色结点时推理类别,绿色结点是训练类别)
Therefore, to recover the probability of any inference node we simply sum the
probabilities of its descendant training nodes